This are the filters of the first convolution layer of Alexnet network. If we look at them, they seem to be interested in luminance patterns (black-gray-white filters) and chrominance patterns (only the colour part without the black-gray-white component). This means that at the beginning the filters are specialized on this two typical situations and after that in the next convolution layer they could be appropriately merged.

To illustrate that, this is the projection of each pixel of the filters (they are really weight vectors with three components red-green-blue). Click on the images to see a 3D representation of the filters components.
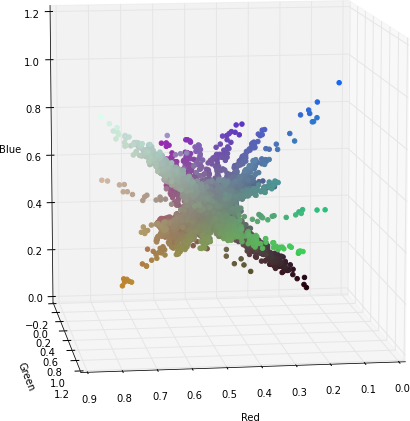
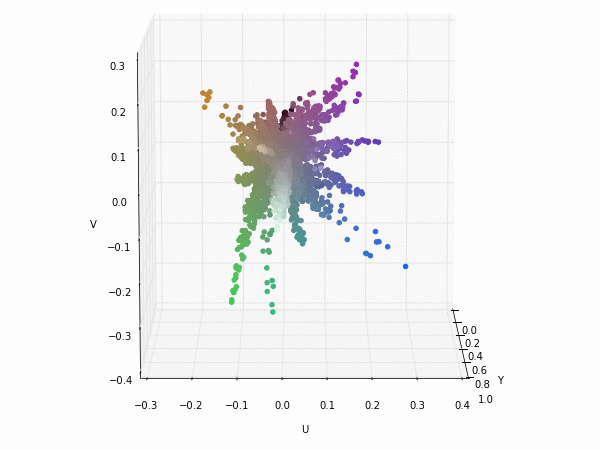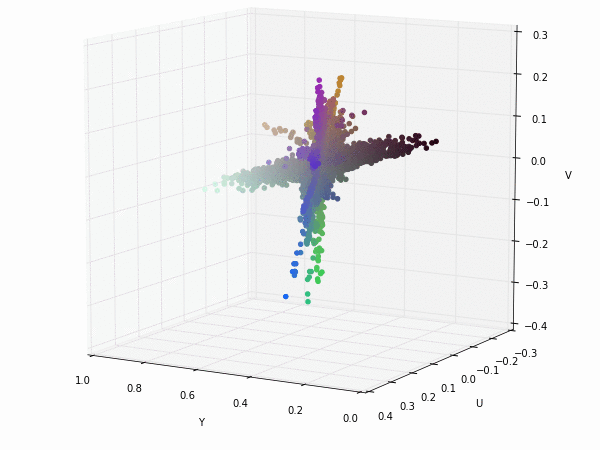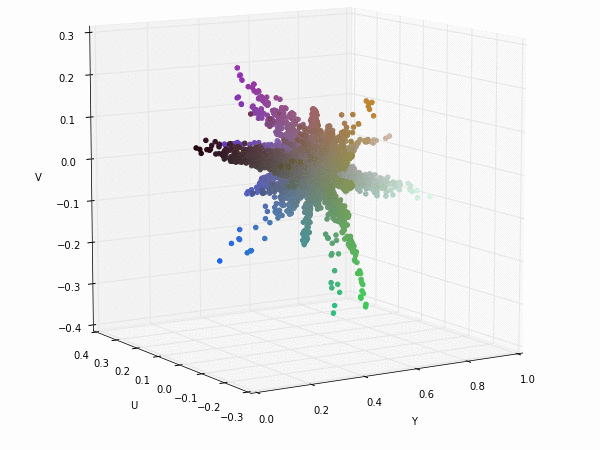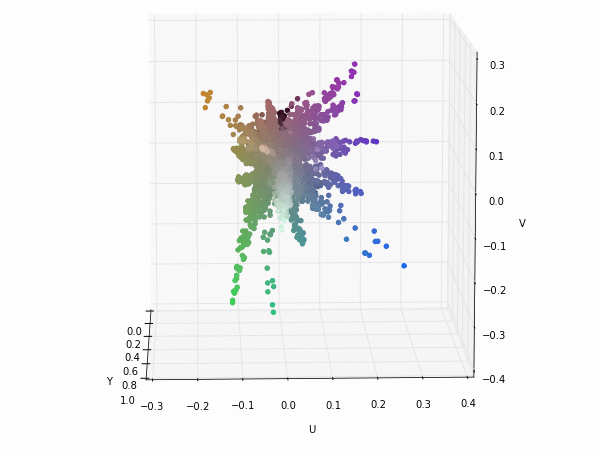
If we apply a transformation to YUV colorspace; also known as YCbCr for digital images. We can see that the Y component (luminance) nearly gets their own axis while UV components (chrominance) are strongly correlated but slightly uncorrelated with the Y component. This means that they could be separated without any problem when training a CNN.
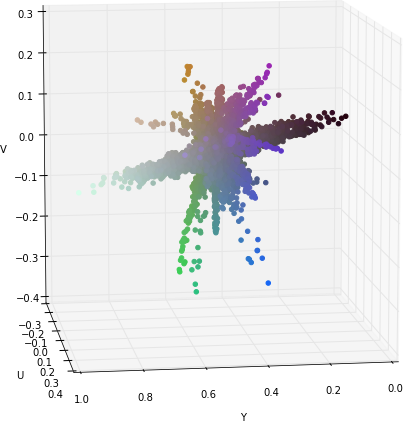 If you find these interesting you can take a look at the results in my Master Thesis:
webpage
or the
pdf
and do not hesitate to ask me any question.
If you find these interesting you can take a look at the results in my Master Thesis:
webpage
or the
pdf
and do not hesitate to ask me any question.
To illustrate that, this is the projection of each pixel of the filters (they are really weight vectors with three components red-green-blue). Click on the images to see a 3D representation of the filters components.
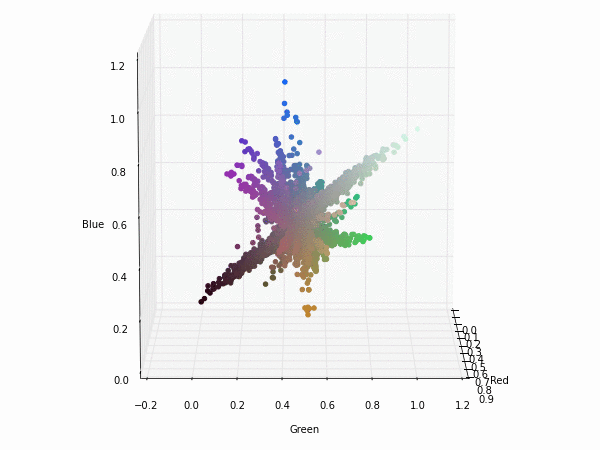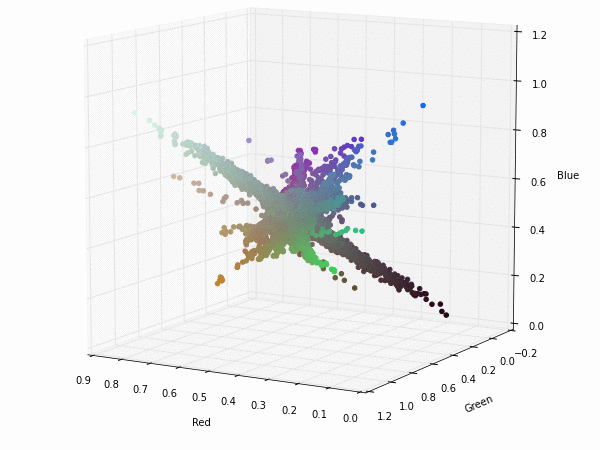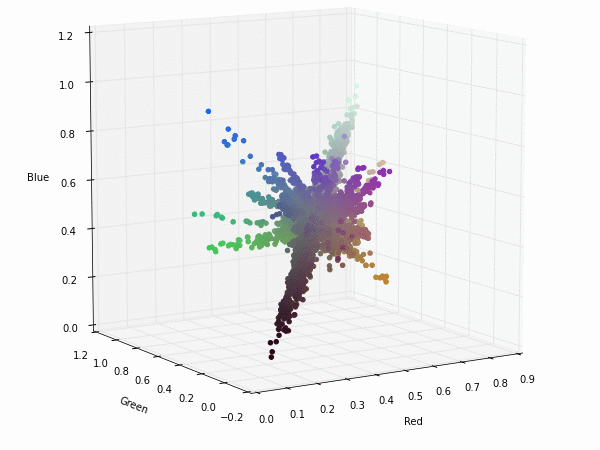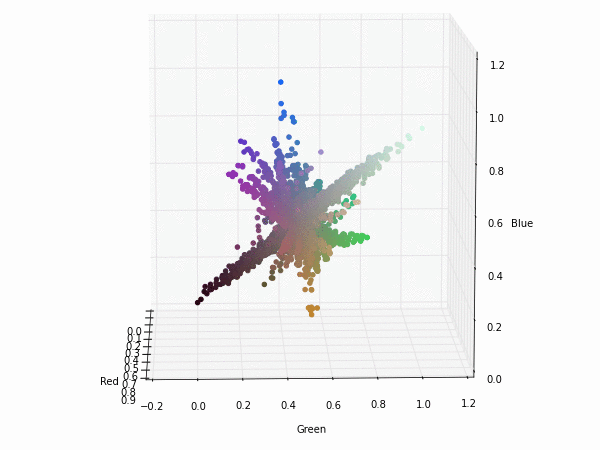
If we apply a transformation to YUV colorspace; also known as YCbCr for digital images. We can see that the Y component (luminance) nearly gets their own axis while UV components (chrominance) are strongly correlated but slightly uncorrelated with the Y component. This means that they could be separated without any problem when training a CNN.
No hay comentarios:
Publicar un comentario